サウンドエフェクタ
ここ数回生成AIの話題が続き、プログラミングとは、というテーマについて(プログラミング教育という観点からも)考えさせられました。
そのような中、CQ出版インターフェイス誌2023/6の特集「デジタル・フィルタ」の中の「Pythonで作るエフェクタ」(青木直史氏著)の記事を見て、過去にPythonライブラリでサウンドエディットプログラムを試したのをおもいだしました。
「LibRosa Sound Edit」
https://decode.red/blog/202008111185/
このときプログラミング自体が創作することだと感じました。
特集にあるPythonプログラムは、デジタルフィルタという数学の世界をプログラムで実装していますが、こういう理論やアルゴリズムを形にするプログラムはこれからもなくならないでしょう。(プログラム言語のテクニックより数学の知識が必要)
記事はとても親切にかかれており、また下記にあるコードを実際に動かしてみましたが、生成された波形データはとても品質の高いものでした。
http://floor13.sakura.ne.jp/cq2023/cq2023.html
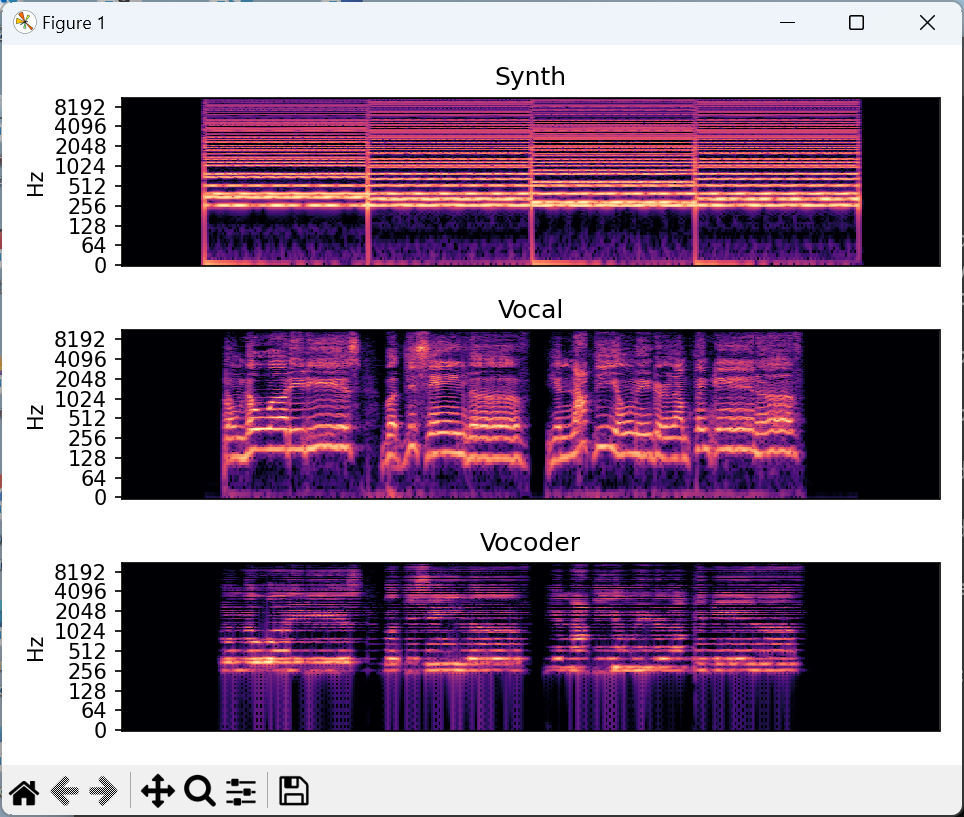
ここではエフェクト出力で一番面白い、ボコーダプログラムで生成した波形のスペクトル表示とそのためのPythonの環境をメモしておきます。
環境) Python 3.9.16 / Windows 11 (Anaconda Navigatorのチャンネルより、conda-forgeを追加しLibrosaをインストール)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import librosa import librosa.display import matplotlib.pyplot as plt import numpy as np #import matplotlib as mpl y, sr = librosa.load("synth(input).wav") Y = librosa.stft(y) plt.figure() plt.subplot(3,1,1) librosa.display.specshow(librosa.amplitude_to_db(np.abs(Y), ref=np.max), y_axis='log') plt.title('Synth') y, sr = librosa.load("vocal(input).wav") Y = librosa.stft(y) plt.subplot(3,1,2) librosa.display.specshow(librosa.amplitude_to_db(np.abs(Y), ref=np.max), y_axis='log') plt.title('Vocal') y, sr = librosa.load("vocoder(output).wav") Y = librosa.stft(y) plt.subplot(3,1,3) librosa.display.specshow(librosa.amplitude_to_db(np.abs(Y), ref=np.max), y_axis='log') plt.title('Vocoder') plt.tight_layout() plt.show() |
ボコーダはシンセサウンドにボーカルのフォルマントを適用します。
※入出力サウンドファイルは上記記事リンクよりダウンロード可
synth(input).wav
vocal(input).wav
vocoder.py
vocoder(output).wav
シンセ波形は、シンセリードのコード変化(Csus4-C-Gsus4-C トップノートだけF-E-D-Eと変化)、ボーカル波形は男性の低い声の歌です。
出力波形は、シンセの音程がボーカルの音程となり、ボーカルのリズムでシンセ音がなるような効果となります。
スペクトルでみてもそれっぽく確認できるから面白いです。
ここでちょっと遊びですが、人の声に近いといわれる、バイオリン音をボーカルの音のかわりに使い音を出力してみました。
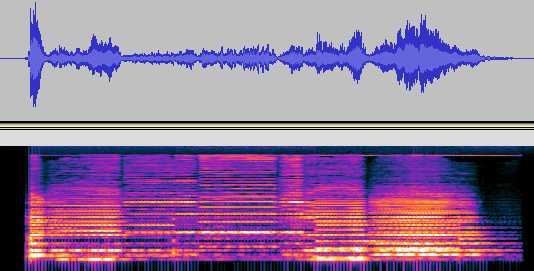
予想しない音になりました。ボコーダのこの特徴だけをぬきとり、他の波形に適用する考え方は、生成AIの世界でもあるようです。
サウンドにはプログラムが活躍する題材が豊富にあります。
リアルタイム性があるものなどは、プロンプトエンジニアリングでは不向きなものがありますので、まだまだプログラミングが必要です。
私がプログラミングを始めたきっかけはサウンドプログラムでした。NEC PC-6001のMMLやサウンドレジスタを操作した”コンピュータの音”が好きで、今でもそれはそれで必要なものと思っています。
このブログでは、意図していなくても結構サウンド関連の記事が多くなっていきました。そこでカテゴリーを追加することにしました。(AM)3Dのときと同じくタイトルがすこし変わります。
AMはAdvanced Musicの略で、Chat GPTでは以下のように説明しています。
先進的というよりはチャレンジ的な試みというつもりです。Algorithmicや生成AIのAという意味もこれからは大きくなる予定です。
Category: AM