
ディープラーニングの手法のひとつであるオートエンコーダについて、下記書籍を参考に自環境で試してみました。
「音楽で身につけるディープラーニング」(北原鉄朗著/オーム社)
環境)Python3 / WSL2 (GeForce)
オートエンコーダというのは、入力と出力に同じデータを与えてネットワークを学習させるもので、中間層には圧縮されたベクトルが得られます。(16次元)
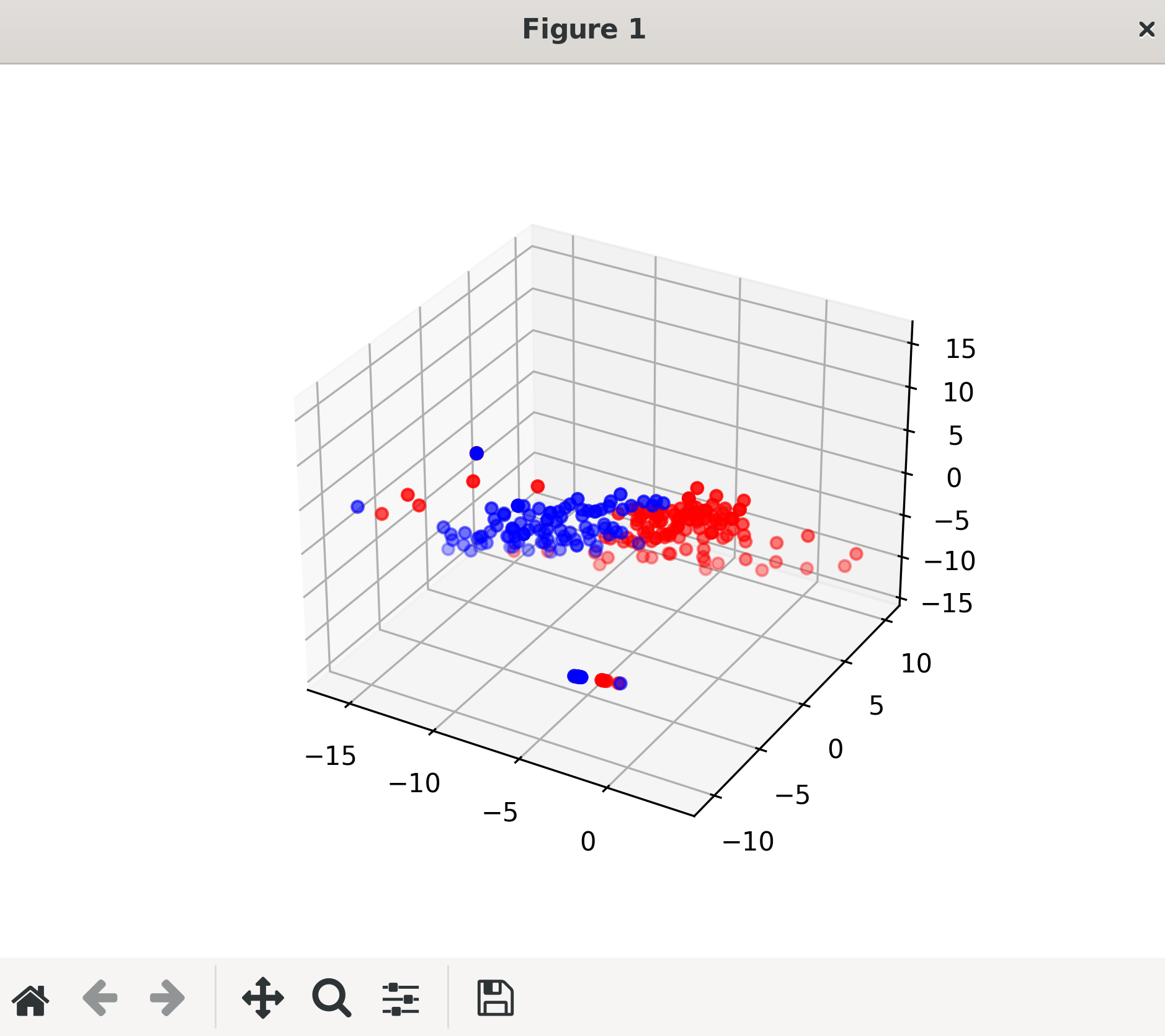
ここでは、3次元についてもテストしていて、3次元は図示できるので再度学習して長調、短調で色分けしています。(とても興味深い結果です)つまりこのベクトルは、データの特徴を表すものとえいます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 |
from input_midi import * from add_rest import * from play_midi import * from sklearn.model_selection import train_test_split import tensorflow as tf # 自感環境用変数 # export PATH=/usr/local/cuda-12.1/bin:$PATH import glob dir = "./midi/" x_all = [] # 入力データ(ソプラノメロディ)を格納する配列 y_all = [] # 出力データ(アルトメロディ)を格納する配列 keymodes = [] # 長調か短調かを格納する配列 files = [] # 読み込んだMIDIファイルのファイル名を格納する配列 for f in glob.glob(dir + "/*.mid"): try: # MIDIファイルを読み込む pr_s, pr_a, keymode = read_midi(f, True, 64) # ピアノロール2値行列に休符要素を追加する x = add_rest_nodes(pr_s) y = add_rest_nodes(pr_a) x_all.append(x) y_all.append(y) keymodes.append(keymode) files.append(f) except UnsupportedMidiFileException: print("skip") # NumPy配列に変換する x_all = np.array(x_all) y_all = np.array(y_all) np.save('x_all', x_all) np.save('y_all', y_all) # 二回目以降データ作成省略用 #x_all = np.load('x_all.npy') #y_all = np.load('y_all.npy') # 学習データとテストデータを分割する i_train, i_test = train_test_split(range(len(x_all)), test_size=int(len(x_all)/2), shuffle=False) x_train = x_all[i_train] x_test = x_all[i_test] y_train = y_all[i_train] y_test = y_all[i_test] # エンコーダ部を実装する seq_length = x_train.shape[1] # 時系列の長さ(時間方向の要素数) input_dim = x_train.shape[2] # 入力の各要素の次元数 encoded_dim = 16 # 何次元ベクトルに圧縮するか lstm_dim = 1024 # RNN(LSTM)層の隠れノード数 # 空のモデルを作る encoder = tf.keras.Sequential() # RMM(LSTM)層を作ってモデルに追加する encoder.add(tf.keras.layers.LSTM( lstm_dim, input_shape=(seq_length, input_dim), use_bias=True, activation="tanh", return_sequences=False)) # 出力層(ノード数はencoded_dim)を作ってモデルに追加する encoder.add(tf.keras.layers.Dense( encoded_dim, use_bias=True, activation="linear")) encoder.summary() # デコーダ部を実装する decoder = tf.keras.Sequential() # 後段のRNN(LSTM)に入力できるように、 # 入力層のベクトルを繰り返して時系列化する decoder.add(tf.keras.layers.RepeatVector( seq_length, input_dim=encoded_dim)) # RNN(LSTM)層を作ってモデルに追加する decoder.add(tf.keras.layers.LSTM( lstm_dim, use_bias=True, activation="tanh", return_sequences=True)) # 出力層を作ってモデルに追加する # (ノード数はエンコーダ部の入力層に合わせる) decoder.add(tf.keras.layers.Dense( input_dim, use_bias=True, activation="softmax")) decoder.summary() encoder.save("model_encoder") decoder.save("model_decoder") # 二回目以降モデル作成省略用 #encoder = tf.keras.models.load_model("model_encoder") #decoder = tf.keras.models.load_model("model_decoder") # エンコーダ部とデコーダ部をドッキングさせる # 入力:エンコーダ部の入力 # 出力:エンコーダ部の出力をデコーダ部に入力して得られる出力 model = tf.keras.Model(encoder.inputs, decoder(encoder.outputs)) # モデルの最後の設定を行う model.compile(optimizer="adam", loss="categorical_crossentropy", metrics="categorical_accuracy") model.summary() # モデルを学習する # x_trainの各要素を入力したら同じものが出力されるようにモデルを学習する model.fit(x_train, x_train, batch_size=32, epochs=1000) # 1000 original model.save_weights('my_checkpoint01') # 二回目以降学習省略用 #model.load_weights('my_checkpoint01') # 精度を評価する model.evaluate(x_train, x_train) model.evaluate(x_test, x_test) # 学習データに対して圧縮・復元を行う # x_trainの各要素をエンコーダ部に入力する(16次元ベクトルが得られる) z = encoder.predict(x_train) # zの各要素をデコーダ部に入力してメロディを再構築する x_new = decoder.predict(z) # 最初のメロディに対して復元結果を確認する k = 0 print(z[k]) # 入力メロディを聴けるようにする show_and_play_midi([x_train[k, :, 0:-1]], "input.mid") # 再構築されたメロディを聴けるようにする show_and_play_midi([x_new[k, :, 0:-1]], "output.mid") # テストデータに対して圧縮・復元を行う # x_testの各要素をエンコーダ部に入力する(16次元ベクトルが得られる) z = encoder.predict(x_test) # zの各要素をデコーダ部に入力してメロディを再構築する x_new = decoder.predict(z) # 最初のメロディに対して復元結果を確認する k = 0 print(z[k]) # 入力メロディを聴けるようにする show_and_play_midi([x_test[k, :, 0:-1]], "input2.mid") # 再構築されたメロディを聴けるようにする show_and_play_midi([x_new[k, :, 0:-1]], "output2.mid") exit() # 上記 encoded_dim = 3 に変更して実行後、下記実行 # x_trainの各要素を3次元ベクトルに変換する z = encoder.predict(x_train) # 得られた3次元ベクトルを長調・短調で色分けして図示する import matplotlib.pyplot as plt from mpl_toolkits.mplot3d.axes3d import Axes3D fig = plt.figure() ax = fig.add_subplot(111, projection='3d') # 学習データのそれぞれに対して長調か短調かの情報を得る key_train = np.array(keymodes)[i_train] # zから長調の楽曲の分だけを抜き出す z_maj = z[key_train[:, 0] == 0, :] # zから短調の楽曲の分だけを抜き出す z_min = z[key_train[:, 0] == 1, :] # z_majの各要素を赤点で描画する ax.scatter(z_maj[:, 0], z_maj[:, 1], z_maj[:, 2], c='red') # z_minの各要素を青点で描画する ax.scatter(z_min[:, 0], z_min[:, 1], z_min[:, 2], c='blue') plt.show() |
学習データとテストデータの評価結果
I tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:432] Loaded cuDNN version 8907
8/8 [==============================] – 2s 105ms/step – loss: 0.0669 – categorical_accuracy: 0.9905
8/8 [==============================] – 1s 105ms/step – loss: 3.8814 – categorical_accuracy: 0.4664
学習データの圧縮、復元結果
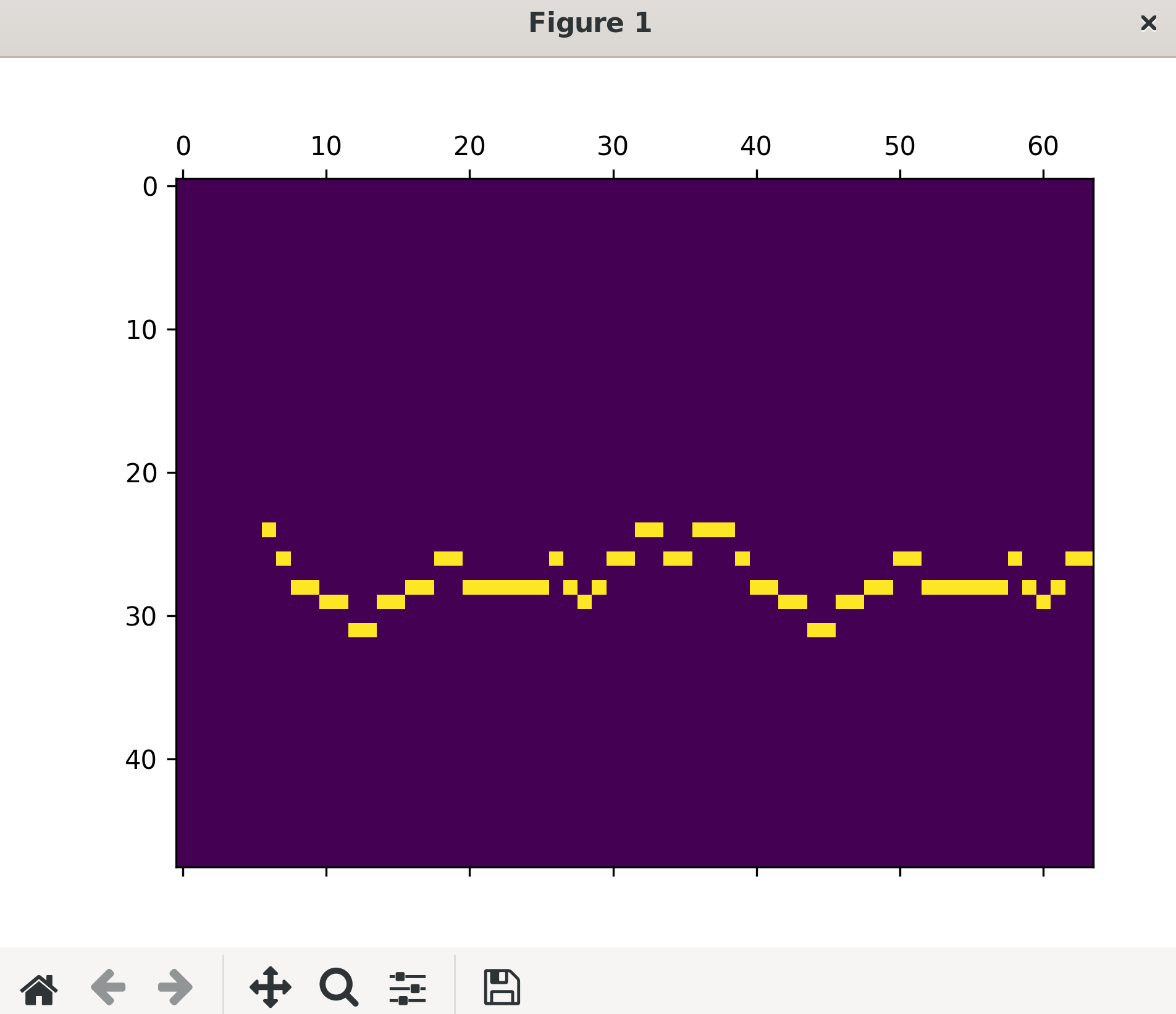
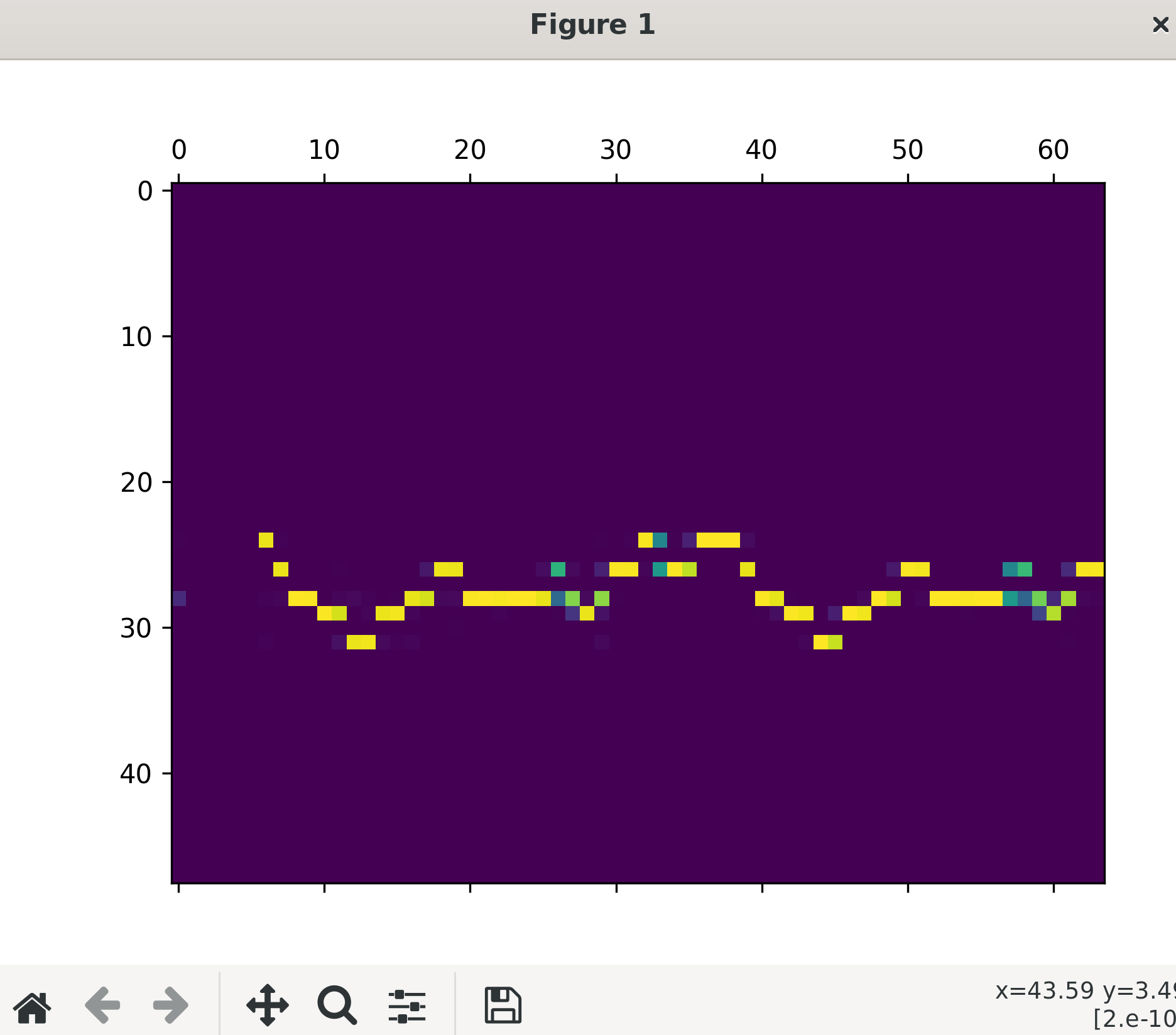
テストデータの圧縮、復元結果
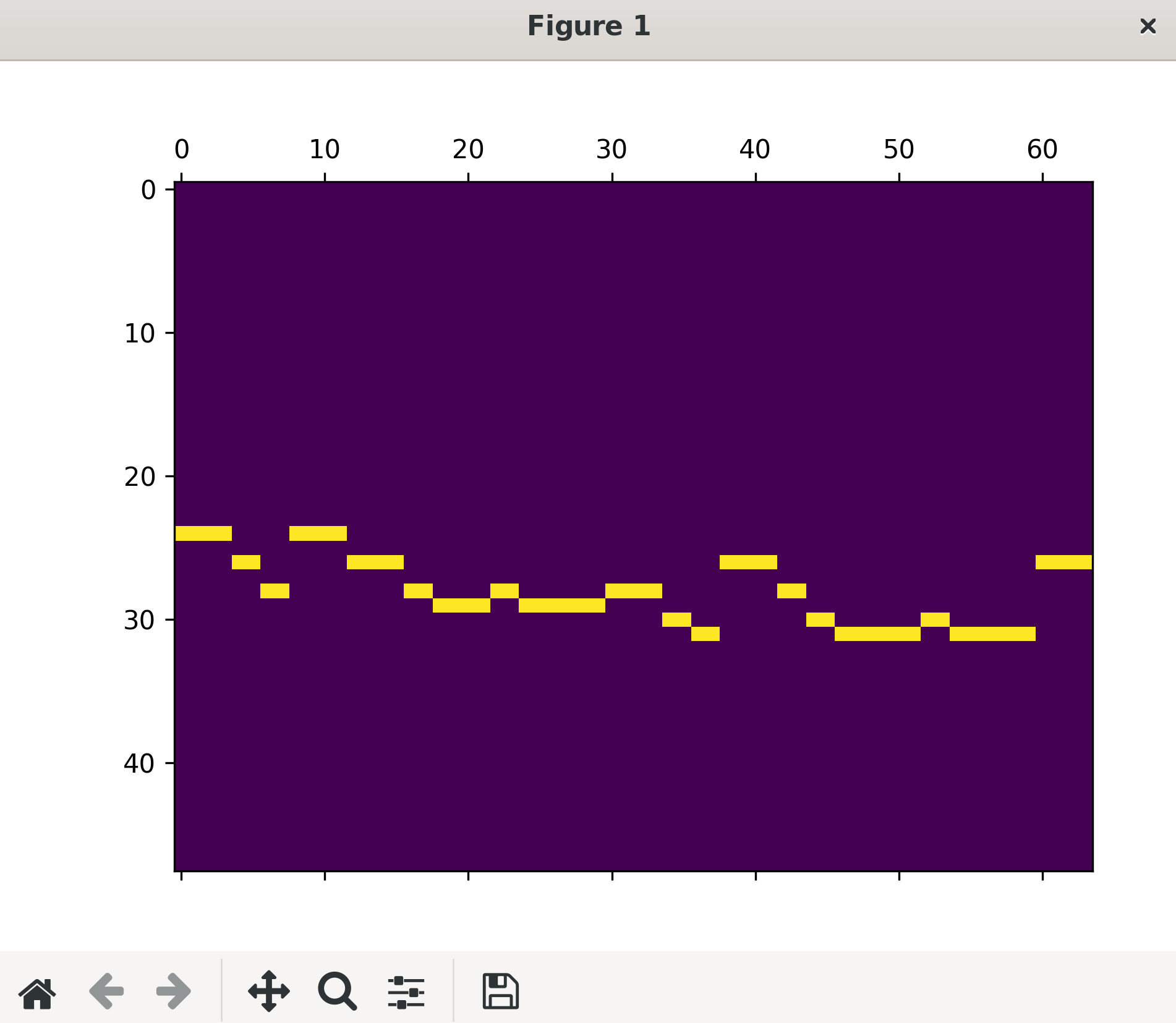
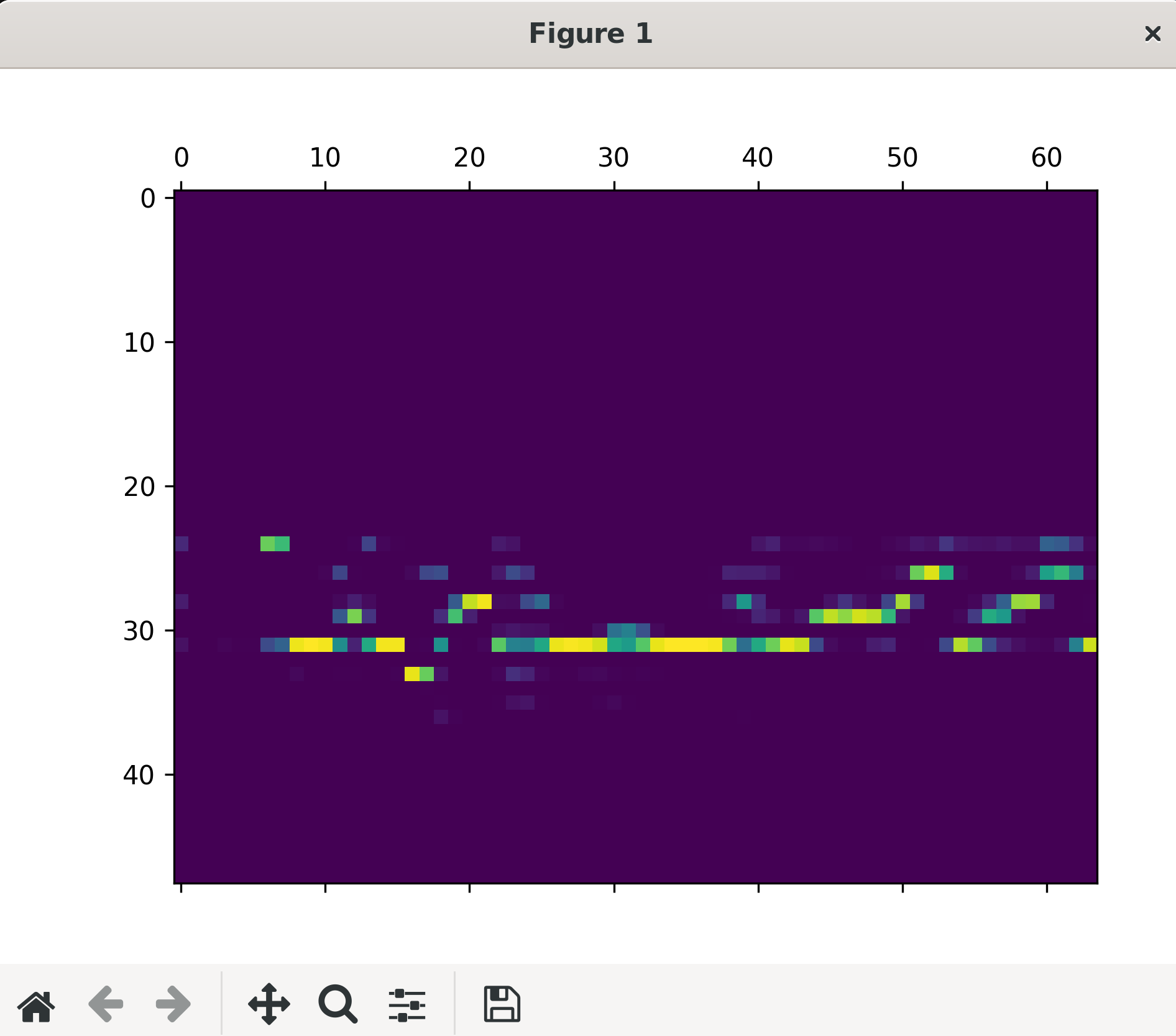
学習データの評価は、そのデータを使って学習していることから復元結果が良く、テストデータはそうでないため結果が良くありません。
長調、短調の色分け
この書籍はオートエンコーダだけでなく、主だったディープラーニングの手法が、具体的なデータを使って解説されてあり、とてもわかりやすいです。音楽としての成果はなかなか難しいところはありますが、音楽データを扱うライブラリがとても充実していてすばらしいです。
関連)
https://decode.red/ed/archives/1600
ライブラリ
input_midi.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import pretty_midi import numpy as np class UnsupportedMidiFileException(Exception): "Unsupported MIDI File" # 与えられたMIDIデータをハ長調またはハ短調に移調 # key_number: 調を表す整数(0--11: 長調、12--23: 短調) def transpose_to_c(midi, key_number): for instr in midi.instruments: if not instr.is_drum: for note in instr.notes: note.pitch -= key_number % 12 # 与えられたMIDIデータからピアノロール2値行列を取得 # nn_from: 音高の下限値(この値を含む) # nn_thru: 音高の上限値(この値を含まない) # seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位) # tempo: テンポ def get_pianoroll(midi, nn_from, nn_thru, seqlen, tempo): pianoroll = midi.get_piano_roll(fs=2*tempo/60) if pianoroll.shape[1] < seqlen: raise UnsupportedMidiFileException pianoroll = pianoroll[nn_from:nn_thru, 0:seqlen] pianoroll = np.heaviside(pianoroll, 0) return np.transpose(pianoroll) # 指定されたMIDIファイルを読み込んでピアノロール2値行列を返却 # filename: 読み込むファイル名 # sop_alto: ソプラノパートとアルトパートを別々に読み込む場合にTrue # seqlen: 読み込む長さ(時間軸方向の要素数、八分音符単位) def read_midi(filename, sop_alto, seqlen): midi = pretty_midi.PrettyMIDI(filename) # 途中で転調がある場合は対象外として例外を投げる if len(midi.key_signature_changes) != 1: raise UnsupportedMidiFileException # ハ長調またはハ短調に移調する key_number = midi.key_signature_changes[0].key_number transpose_to_c(midi, key_number) # 長調(keymode=0)か短調(keynode=1)かを取得する keymode = np.array([int(key_number / 12)]) # 途中でテンポが変わる場合は対象外として例外を投げる tempo_time, tempo = midi.get_tempo_changes() if len(tempo) != 1: raise UnsupportedMidiFileException if sop_alto: # パート数が2未満の場合は対象外として例外を投げる if len(midi.instruments) < 2: raise UnsupportedMidiFileException # ソプラノ(1パート目)とアルト(2パート目)のそれぞれに対して # ピアノロール2値行列を取得する pr_s = get_pianoroll(midi.instruments[0], 36, 84, seqlen, tempo[0]) pr_a = get_pianoroll(midi.instruments[1], 36, 84, seqlen, tempo[0]) return pr_s, pr_a, keymode else: # 全パートを1つにしたピアノロールを取得する pr = get_pianoroll(midi, 36, 84, seqlen, tempo[0]) return pr, keymode |
add_rest.py
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np # ピアノロール2値行列に休符要素を追加する def add_rest_nodes(pianoroll): # ピアノロール2値行列の時刻ごとの各音高ベクトルに対して、 # 全要素が0のときに1、そうでないときに0を格納したデータ # (休符要素系列と呼ぶ)を作る rests = 1 - np.sum(pianoroll, axis=1) # 休符要素系列に2次元配列化して行列として扱えるようにする rests = np.expand_dims(rests, 1) # ピアノロール2値行列と休符要素系列をくっつけた行列を作って返す return np.concatenate([pianoroll, rests], axis=1) |
play_midi.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from out_midi import * import matplotlib.pyplot as plt #import IPython.display as ipd import pretty_midi from midi2audio import FluidSynth import numpy as np # 与えられたピアノロール2値行列からMIDIデータを作るのに加え、 # ピアノロール2値行列を描画したり、再生できるようにする def show_and_play_midi(pianorolls, filename): # ピアノロール2値行列を描画する for pr in pianorolls: plt.matshow(np.transpose(pr)) plt.show() # MIDIデータを生成してファイルに保存する make_midi(pianorolls, filename) # MIDIデータをwavに変換してブラウザ上で聴けるようにする #fs = FluidSynth(sound_font="/usr/share/sounds/sf2/FluidR3_GM.sf2") #fs.midi_to_audio(filename, "output.wav") #ipd.display(ipd.Audio("output.wav")) |