
Posted on 2021/09/05, 4:27 PM By admin22
前回のRを使ってベイズ推定にとりかかろうとStanの勉強をはじめました。
StanはRから独立したものですが、Rから使うことが多いということで、Rの一部分として理解しようと思っています。
「Stan超初心者入門 」
とてもわかりやすい説明で参考にさせていただきました。
他の書籍などで、モデルで推定したデータなのか、実際のサンプリングデータなのかどちらわかりづらかったのですが、二項分布binomial.stanのシンプルなコードを見て理解できました。
ここでは正規分布の確率モデルで推定をやってみました。
test.stan(Home Directory にrというディレクトリを作ってその下に格納した)
平均 0.3、標準偏差0.1のモデルを記述しpを推定
|
1 2 3 4 5 6 |
parameters{ real<lower=0, upper=1> p; } model{ p ~ normal(0.3, 0.1); } |
R Consloeでの操作
|
1 2 3 4 5 |
> library(rstan) > fit<-stan("r/test.stan") > stan_hist(fit, pars="p") > pp<-rstan::extract(fit)$p > hist(pp) |
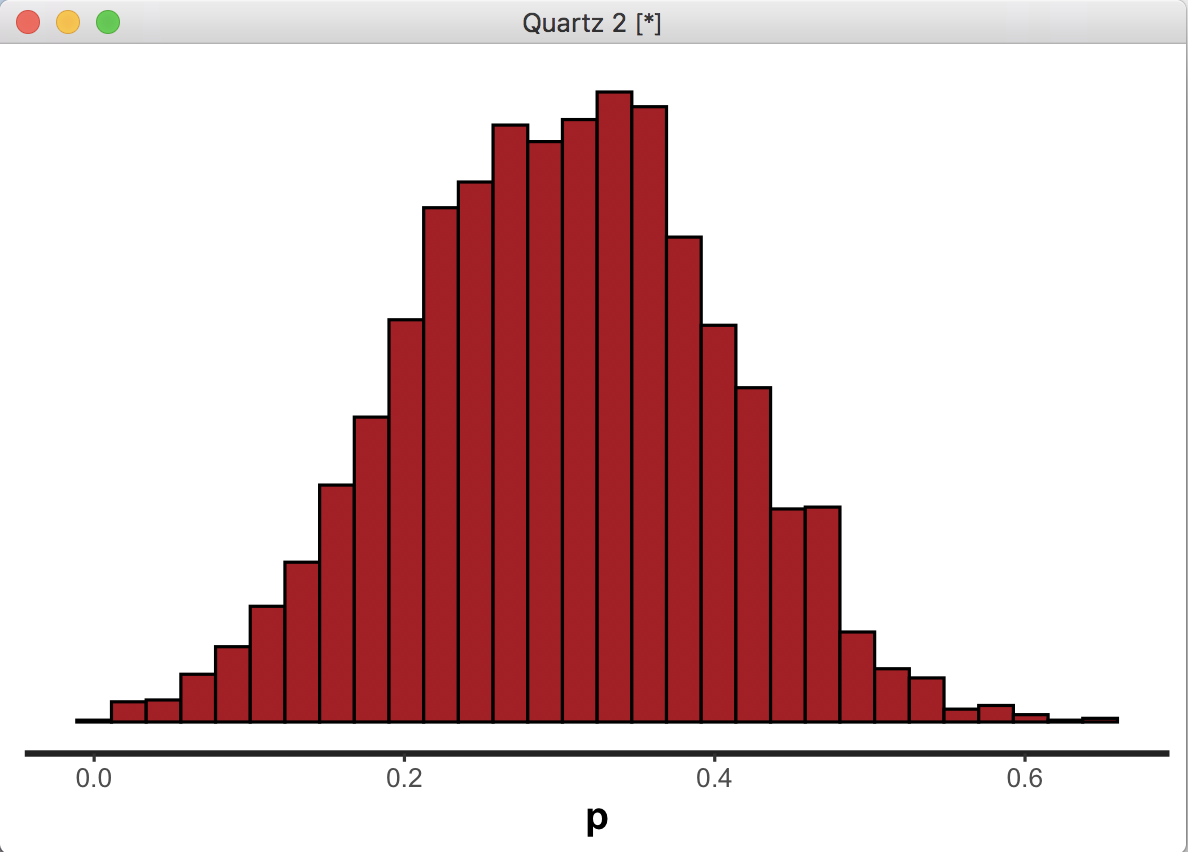
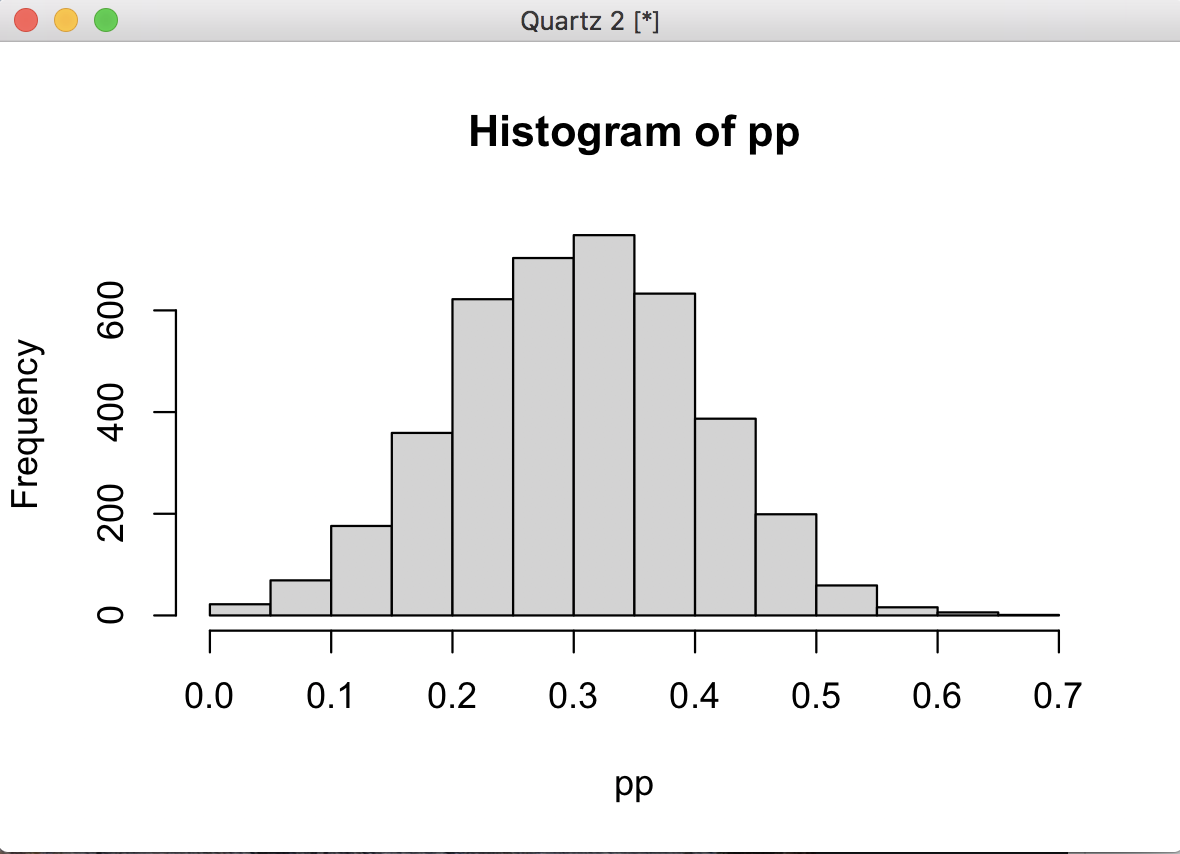
上がStanのヒストグラム、下がRのヒストグラムです。Stanの領域とRの領域は別なので変数名はpのままでよかったのですが、わかりやすくするために分けました。これでStanで生成したデータがRで使えることが確認できました。
特徴的なのはStanのモデル定義にある”〜”です。プログラムというのは具体的に物事を記述しますが、このような抽象的表現で記述されることが斬新でした。しかも動的言語でなく静的言語C++にコンパイルされているとのことです。
まだまだ入り口ですが、次に進めたいと思います。
Categories: 未分類 タグ: R