
Posted on 2021/07/17, 2:10 PM By admin22
「Q学習(Qがくしゅう、英: Q-learning)は、機械学習分野における強化学習の一種である。」
https://ja.wikipedia.org/wiki/Q%E5%AD%A6%E7%BF%92
「はじめての強化学習〜Q-learningで迷路を解く〜」
https://qiita.com/fujina_u2/items/f407a1ca143e0bbc4446
Qラーニングについて、とてもわかりやすく解説と実装されている上記サイトをみて、試してみることにしました。
コードはそのままですが、自分の理解のために詳しくコメントしてみました。
簡単に説明すると、Q値と呼ばれる行動を判定する値を、繰り返し補正しながら適正な値に調整していく仕組みです。そのため報酬と呼ばれる概念が使われます。その結果を選びやすくするわけです。
そのため結果から遡って、その過程のQ値を調整します。
このサイトでは、下のようなグラフ構造を用いて、ノード11に500とノード14に1000という報酬を与え、その経路が選びやすくなっていくことを説明しています。
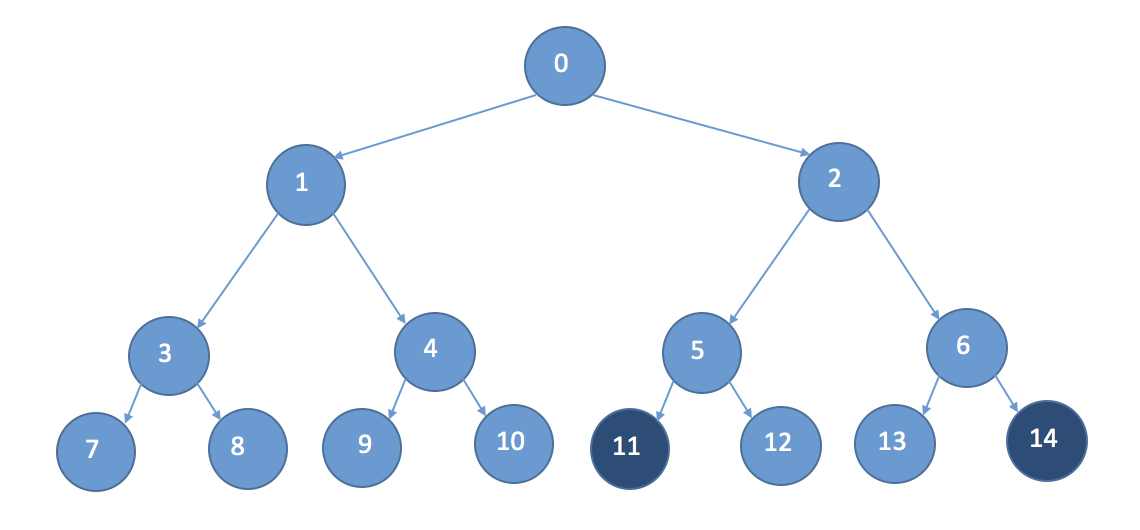
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
#include<stdio.h> #include<stdlib.h> #define NODENO 15 //Q値のノード数 #define GENMAX 1000 //学習の繰り返し回数 #define ALPHA 0.1 //学習係数 #define GAMMA 0.9 //割引率 #define EPSILON 0.3 //行動選択のランダム性を決定(閾値) #define DEPTH 3 //道のりの深さ #define SEED 3277 /*乱数*/ double rand1(){ //0~1 return (double)rand()/RAND_MAX; } int rand01(){ //0or1 int rnd; while((rnd=rand())==RAND_MAX); return (int)((double)rnd/RAND_MAX*2); } int rand100(){ //0~100 int rnd; while((rnd=rand())==RAND_MAX); return (int)((double)rnd/RAND_MAX*101); } /*Q値表示*/ void print_Q(int idx, int *qvalue){ printf("[%d] ", idx); for(int i=1 ;i<NODENO; i++) printf("%d)%d\t", i, qvalue[i]); printf("\n"); } int update_Q(int s,int *qvalue){ int qv; //更新されるQ値 int qmax; //Q値の最大値 if(s > 6){ //最下段 : 自身の値を更新 if(s == 14){ qv = qvalue[s] + ALPHA * (1000 - qvalue[s]); //報酬の付与(1000) } else if(s == 11){ qv = qvalue[s] + ALPHA * (500 - qvalue[s]); //報酬の付与(500) } else{ qv = qvalue[s]; //そのまま } } else{ //最下段以外 : 下段の値を用いて更新 if(qvalue[2 * s + 1] > qvalue[2 * s + 2]){ qmax = qvalue[2 * s + 1]; // *2 +1 は下の段の左 } else{ qmax = qvalue[2 * s + 2]; // *2 +2 は下の段の右 } qv = qvalue[s] + ALPHA * (GAMMA * qmax - qvalue[s]); } return qv; } /*行動を選択(ε-greedy)*/ int select_action(int olds,int *qvalue){ int s; if(rand1() < EPSILON){ //ランダムに行動 if(rand01() == 0){ s = 2 * olds + 1; // *2 +1 は下の段の左 } else{ s = 2 * olds + 2; // *2 +2 は下の段の右 } } else{ //ランダムに行動しない場合は、Q値最大値を選択 if(qvalue[2 * olds + 1] > qvalue[2 * olds + 2]){ s = 2 * olds + 1; } else{ s = 2 * olds + 2; } } return s; } int main(){ int qvalue[NODENO]; //Q値 int s; //状態 int t; //時間 srand(SEED); //Q値の初期化 for(int i=0; i<NODENO; i++){ qvalue[i] = rand100(); } print_Q(0, qvalue); for(int i = 0; i<GENMAX; i++){ s = 0; //行動の初期化 for(t=0; t<DEPTH; t++){ s = select_action(s, qvalue); //行動選択 qvalue[s] = update_Q(s, qvalue); //Q値の更新 } print_Q(i+1, qvalue); } return 0; } |
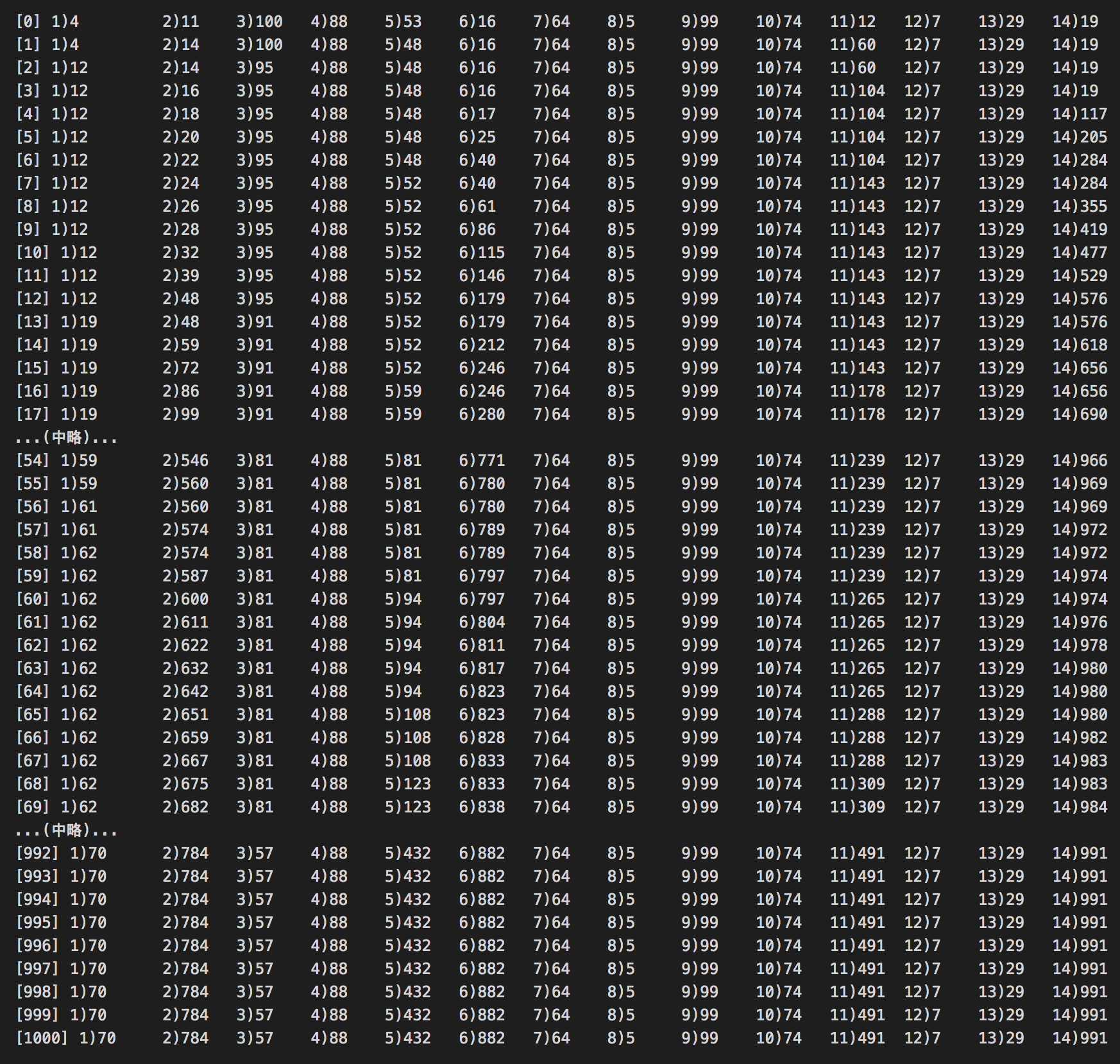
2,5,6,11,14の値がだんだん大きくなっています。
1より2、5より6、11より14が大きく、そして11,14が報酬値に近いのがわかります。
数式で説明されると何かと難しく感じるのですが、コードにすると理解が進みます。
Categories: 未分類 タグ: C, Machine Learning