
機械学習で画像データなどを扱っていると、学習させるデータの前処理というものがとても重要だということに気づかされます。結局のところ対象にするデータの特徴について詳しく学ぶ必要がでてきます。
ここでは音の識別、分類のための特徴抽出によく使われるPythonの解析ライブラリのLibrosaについて、テストしてみました。
https://librosa.org/
環境: Jupyter Notebook/ Anacoda / Windows
インストールは依存関係が複雑なのでAnacondaが便利です。
conda install -c conda-forge librosa
Sound File: R1.wav(Roland MC-505 Preset Pattern 75)
まずは、オリジナルデータの読み込みとその再生確認。
それを短い音(打楽器)と長い音(メロディーなど)を分離する優れた機能を使って二つの波形を作ってみます。(それぞれコメントを切り替えて再生確認。波形の保存はSoundCloudで聴くためのアップロード用)

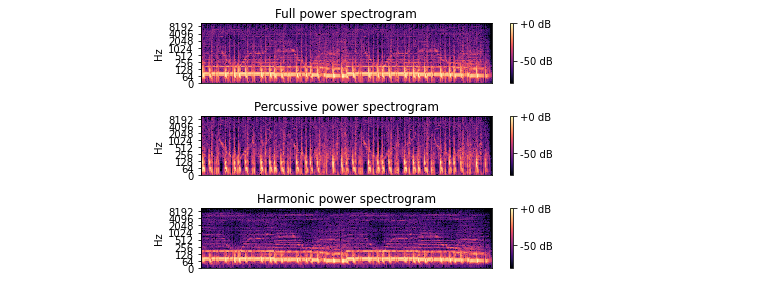
オリジナル、パーカッシブ、ハーモニックのスペクトグラムをプロットします。
次は、今回やりたかったスペクトグラムという「画像」を編集して音に戻して聴くというものです。スペクトグラムは音の周波数を表しているので、高い音と低い音をカットする意図でその部分の配列の値を0にしています。
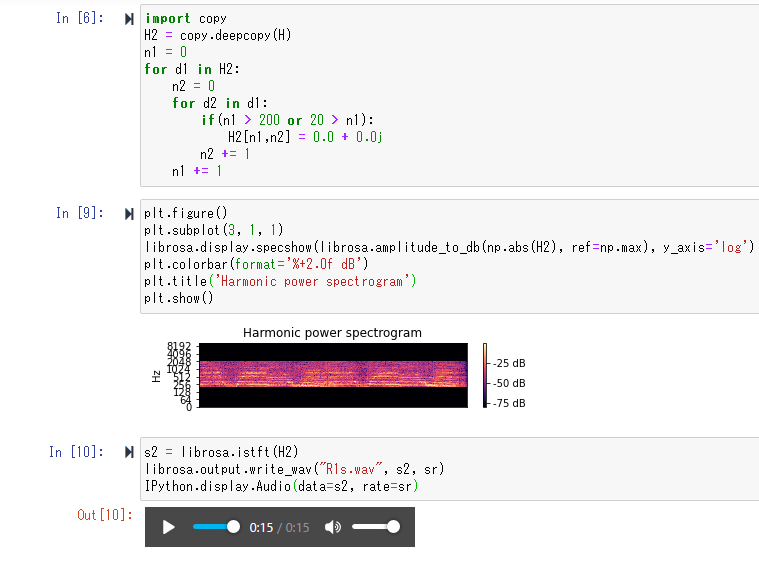
オリジナルでは聴こえなかった音が聴こえてきました。さらに解析を進めて音程を抽出することもできるでしょう。
以下、ここまでで生成した、オリジナル、ハーモニック、パーカッシブ、ハーモニック編集、という順で音を確認できるようにしました。(各15秒)
どんなデータも特徴抽出というものがきちんとできることが、そのデータを使った分類処理等を有効なものにすると思います。音楽はテンポがかわってもキー(調整)が変わっても同じものと認識できますが、画像としてのパターンを比較することで容易になるのではと思っています。未知のコンピュータウィルスの検出もファイルを画像化して、画像の領域で分析すると聞いたことがあります。パターンというのは周波数領域の視点と考えますが、音楽はこれを扱うことが得意ですので、ヒントになる材料が多く潜んでいる可能性を感じます。
(しかしサウンドエフェクタとしての性能がすごすぎて、こちらに夢中になってしまいそうです。)
参考: https://qiita.com/__Attsun__/items/e033d689c336315435b3