
Posted on 2025/10/12, 10:46 AM By admin22
Unslothをつかったファインチューニングをためしてみました。
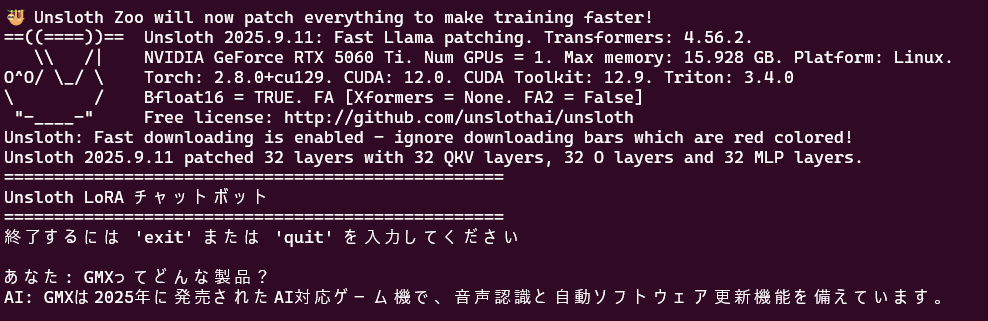
ファインチューニングといえば、かなり重いイメージがありましたが、このライブラリをつかうことで16GBのGPUメモリで数分で終わりました。データ数がすくなくモデルも軽いという点もありますが、いい実験になります。
データがすくないので、過学習になってしまいますが、学習効果を確認できることは、気持ちいいです。
学習データ(new_knowledge.json)
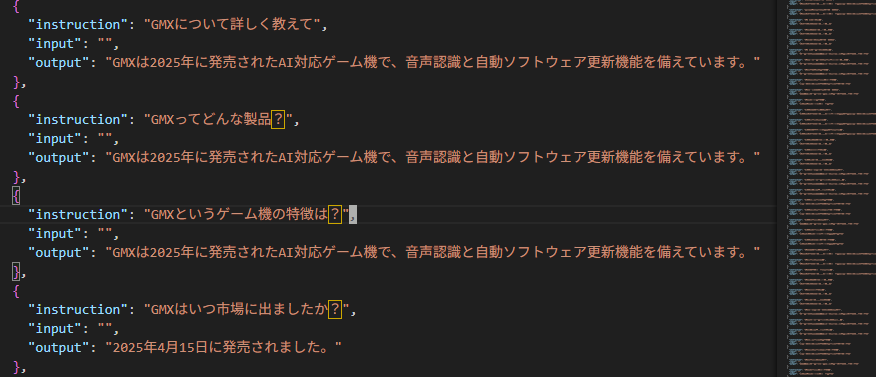
学習
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# Unsloth + Hugging Face + QLoRA で知識注入 import torch from unsloth import FastLanguageModel from datasets import load_dataset from trl import SFTTrainer, SFTConfig # ① ベースモデルをロード model, tokenizer = FastLanguageModel.from_pretrained( "meta-llama/Meta-Llama-3-8B-Instruct", load_in_4bit=True, # QLoRA用:4bit量子化 max_seq_length=2048, ) # ② データセットをロード dataset = load_dataset("json", data_files="new_knowledge.json", split="train") # データセットをフォーマット(テキストフィールドを追加) def format_dataset(example): # Llama 3のチャット形式を使用 text = f"<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n{example['instruction']}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n{example['output']}<|eot_id|>" return {"text": text} dataset = dataset.map(format_dataset, remove_columns=dataset.column_names) # ③ LoRA アダプタを作成 model = FastLanguageModel.get_peft_model( model, r=16, # rank を増やして学習能力向上 target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], # 全ての線形層を対象 lora_alpha=16, lora_dropout=0, bias="none", use_gradient_checkpointing="unsloth", ) # ④ ファインチューニング trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=dataset, dataset_text_field="text", max_seq_length=2048, args=SFTConfig( per_device_train_batch_size=1, # バッチサイズを小さく gradient_accumulation_steps=4, warmup_steps=10, num_train_epochs=20, # 小さいデータセットなのでエポックを増やす max_steps=60, # 最大ステップ数を制限 learning_rate=5e-4, # 学習率を上げて強く学習 fp16=not torch.cuda.is_bf16_supported(), bf16=torch.cuda.is_bf16_supported(), logging_steps=1, optim="adamw_8bit", weight_decay=0.001, # weight decayを下げる lr_scheduler_type="linear", seed=3407, output_dir="outputs", save_strategy="steps", save_steps=20, save_total_limit=3, load_best_model_at_end=False, ), ) trainer.train() # ⑤ 保存 model.save_pretrained("llama3-x1000-lora") tokenizer.save_pretrained("llama3-x1000-lora") |
推論
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
# Unsloth LoRA チャットボット推論プログラム import torch from unsloth import FastLanguageModel # ① モデルとLoRAアダプタをロード model, tokenizer = FastLanguageModel.from_pretrained( model_name="llama3-x1000-lora", # 学習済みLoRAアダプタのパス max_seq_length=2048, load_in_4bit=True, ) # 推論モードに設定 FastLanguageModel.for_inference(model) # ② チャット関数 def chat(instruction): # Llama 3のチャット形式でプロンプトをフォーマット prompt = f"<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n{instruction}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" # トークナイズ inputs = tokenizer([prompt], return_tensors="pt").to("cuda") input_length = inputs.input_ids.shape[1] # 生成 outputs = model.generate( **inputs, max_new_tokens=256, temperature=0.3, # 温度を下げて正確性向上 top_p=0.9, do_sample=True, repetition_penalty=1.15, use_cache=True, eos_token_id=tokenizer.eos_token_id, ) # 入力部分を除いて新しく生成された部分のみデコード generated_ids = outputs[0][input_length:] response = tokenizer.decode(generated_ids, skip_special_tokens=True) return response.strip() # ③ 対話ループ def main(): print("=" * 50) print("Unsloth LoRA チャットボット") print("=" * 50) print("終了するには 'exit' または 'quit' を入力してください") print() while True: # ユーザー入力 user_input = input("あなた: ").strip() # 終了チェック if user_input.lower() in ['exit', 'quit', '終了']: print("チャットボットを終了します。") break if not user_input: continue # 推論実行 print("AI: ", end="", flush=True) response = chat(user_input) print(response) print() if __name__ == "__main__": main() |
Categories: 未分類