
Posted on 2025/09/06, 2:30 PM By admin22
ハイブリッド検索RAGのテストです。
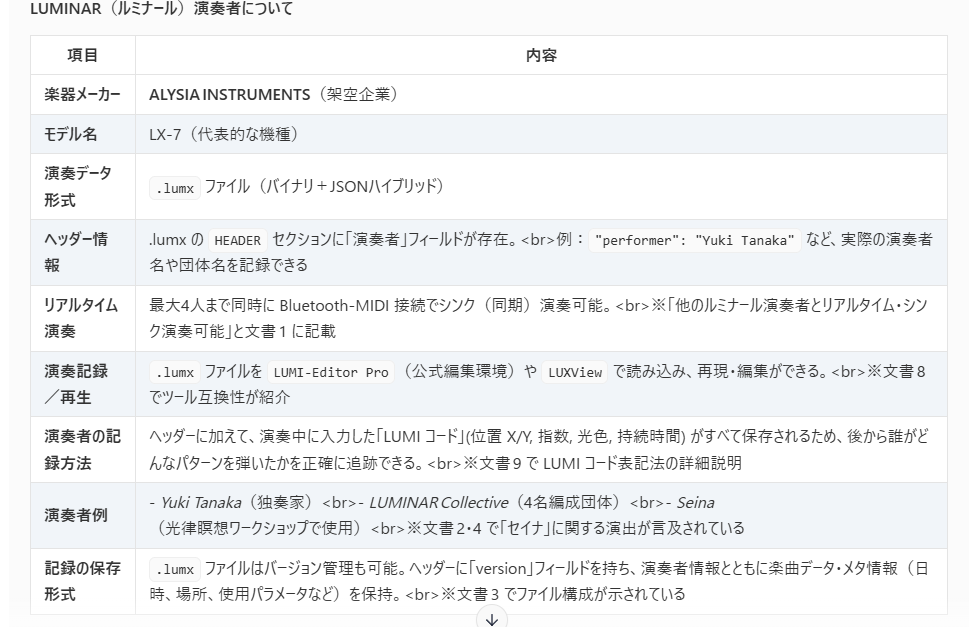
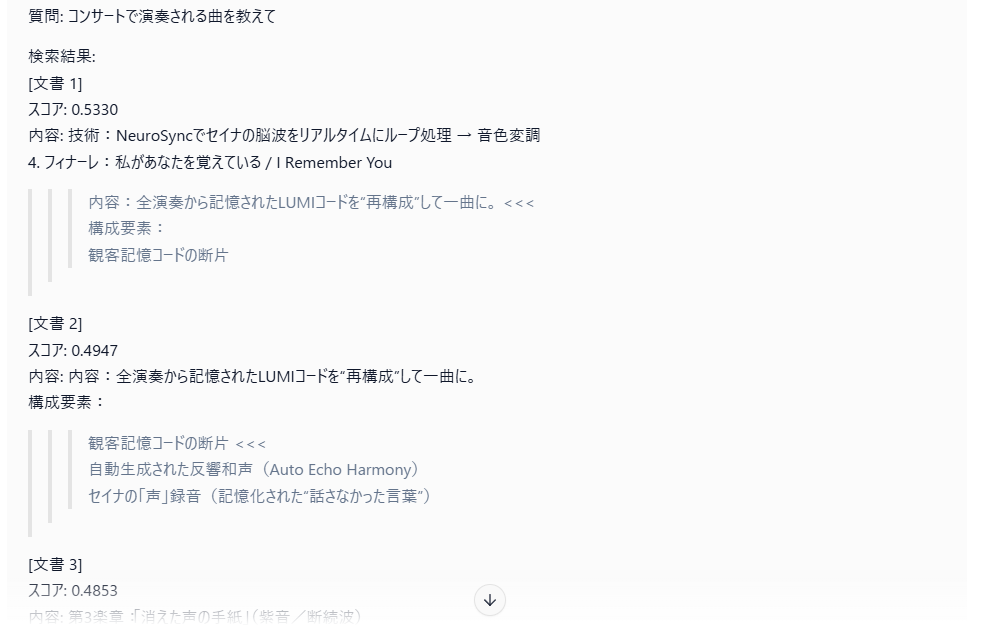
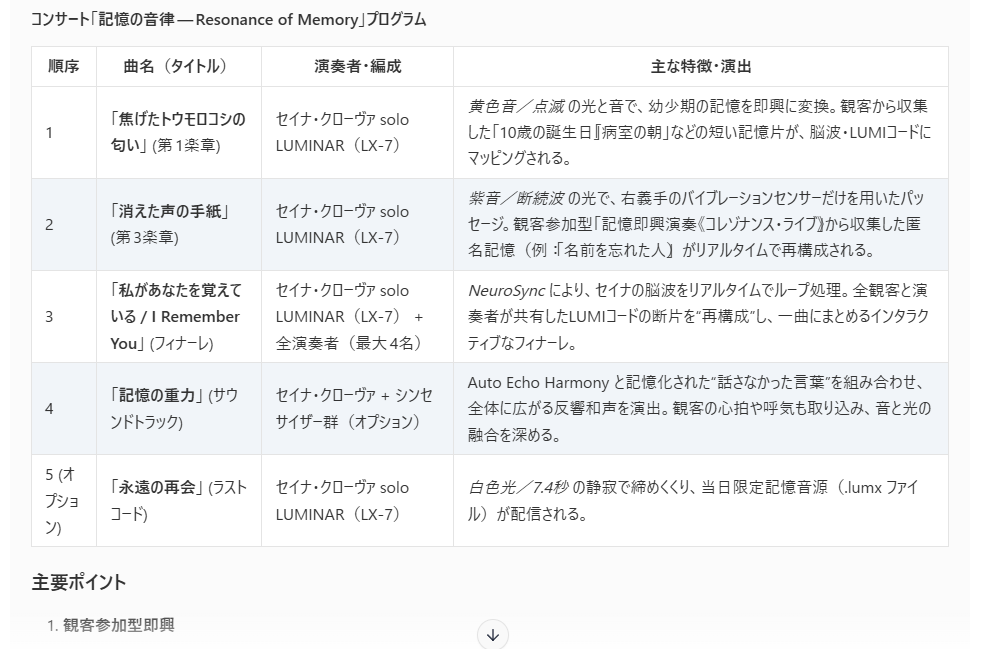
上記でもつかった架空の楽器についてかかれたテキストに対して、ベクトル検索、キーワード検索をします。
検索結果をLLMの質問に付加して、これをLM Studio(GPT-OSS-20B)のプロンプトに入力しました。
何をやっているのかわかりやすくするため、手動で作業しました。
下記コードは、検索結果をリランキングして表示するものです。
ベクトル検索とキーワード検索のクエリを同じにすることは、それぞれの性質を考えた場合、適当でないと考えたため、別のものとしました。
このような検索の仕方がいいのかどうか、このあたりは試行錯誤中です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 |
import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity from sentence_transformers import SentenceTransformer import re from typing import List, Dict, Tuple import json class HybridRAGSystem: def __init__(self, embedding_model_name='all-MiniLM-L6-v2'): """ ハイブリッド検索RAGシステム キーワード検索(TF-IDF)とベクトル検索を組み合わせ """ self.embedding_model = SentenceTransformer(embedding_model_name) # 日本語対応のTF-IDFベクトライザー self.tfidf_vectorizer = TfidfVectorizer( stop_words=None, # 日本語なので英語ストップワードを無効化 ngram_range=(2, 4), # 2-4文字のn-gramで日本語の語彙をカバー max_features=10000, analyzer='char', # 文字ベースの解析で日本語に対応 token_pattern=None, # analyzerがcharの場合は不要 min_df=1 # 最小文書頻度を1に設定(稀な語も含める) ) # データストレージ self.documents = [] self.document_embeddings = None self.tfidf_matrix = None self.is_indexed = False def add_documents(self, texts: List[str]): """ 文書をシステムに追加 """ self.documents.extend(texts) print(f"追加された文書数: {len(texts)}") print(f"総文書数: {len(self.documents)}") def build_index(self): """ インデックスを構築(ベクトル埋め込み + TF-IDFマトリックス) """ if not self.documents: raise ValueError("文書が追加されていません") print("インデックスを構築中...") # ベクトル埋め込みの生成 print("ベクトル埋め込みを生成中...") self.document_embeddings = self.embedding_model.encode( self.documents, show_progress_bar=True, convert_to_numpy=True ) # TF-IDFマトリックスの構築 print("TF-IDFマトリックスを構築中...") self.tfidf_matrix = self.tfidf_vectorizer.fit_transform(self.documents) self.is_indexed = True print("インデックス構築完了!") def keyword_search(self, query: str, top_k: int = 10, return_all_scores: bool = False) -> List[Tuple[int, float]]: """ キーワード検索(TF-IDF) """ if not self.is_indexed: raise ValueError("インデックスが構築されていません") # コサイン類似度の計算 query_vector = self.tfidf_vectorizer.transform([query]) similarities = cosine_similarity(query_vector, self.tfidf_matrix)[0] if return_all_scores: # 全文書のスコアを返す return [(idx, similarities[idx]) for idx in range(len(similarities))] # スコアでソートして上位K件を返す top_indices = np.argsort(similarities)[::-1][:top_k] results = [(idx, similarities[idx]) for idx in top_indices if similarities[idx] > 0] return results def vector_search(self, query: str, top_k: int = 10) -> List[Tuple[int, float]]: """ ベクトル検索(意味的類似度) """ if not self.is_indexed: raise ValueError("インデックスが構築されていません") # クエリを埋め込みベクトルに変換 query_embedding = self.embedding_model.encode([query]) # コサイン類似度の計算 similarities = cosine_similarity( query_embedding, self.document_embeddings )[0] # スコアでソートして上位K件を返す top_indices = np.argsort(similarities)[::-1][:top_k] results = [(idx, similarities[idx]) for idx in top_indices] return results def hybrid_search( self, query: str, top_k: int = 10, keyword_weight: float = 0.3, vector_weight: float = 0.7, rerank: bool = True, context_lines: int = 2, keyword_query: str = None ) -> List[Dict]: """ ハイブリッド検索(近隣行を含むコンテキスト付き) Args: query: ベクトル検索用のクエリ top_k: 返す結果数 keyword_weight: キーワード検索の重み vector_weight: ベクトル検索の重み rerank: リランキングを行うか context_lines: 前後何行を含めるか keyword_query: キーワード検索専用クエリ(None の場合は query を使用) """ if not self.is_indexed: raise ValueError("インデックスが構築されていません") # 各検索手法で結果を取得(全スコアを取得) # キーワード検索用クエリの決定 actual_keyword_query = keyword_query if keyword_query is not None else query print(f"Debug: ベクトル検索クエリ: '{query}'") print(f"Debug: キーワード検索クエリ: '{actual_keyword_query}'") keyword_all_scores = self.keyword_search(actual_keyword_query, top_k, return_all_scores=True) vector_results = self.vector_search(query, top_k * 2) # キーワードスコア辞書を作成 keyword_scores_dict = {idx: score for idx, score in keyword_all_scores} print(f"\nDebug: キーワード検索結果数: {len([s for s in keyword_all_scores if s[1] > 0])}") print(f"Debug: ベクトル検索結果数: {len(vector_results)}") if vector_results: print(f"Debug: ベクトル検索上位3件: {vector_results[:3]}") # スコアを統合 combined_scores = {} # ベクトル検索の結果を追加 for doc_idx, score in vector_results: combined_scores[doc_idx] = combined_scores.get(doc_idx, 0) + vector_weight * score # キーワードスコアも追加 keyword_score = keyword_scores_dict.get(doc_idx, 0.0) combined_scores[doc_idx] += keyword_weight * keyword_score # スコアでソートして上位K件を選択 sorted_results = sorted( combined_scores.items(), key=lambda x: x[1], reverse=True )[:top_k] # 結果を整形(コンテキスト行を含む) results = [] vector_scores_dict = {idx: score for idx, score in vector_results} for doc_idx, combined_score in sorted_results: # 個別スコアも取得 keyword_score = keyword_scores_dict.get(doc_idx, 0.0) vector_score = vector_scores_dict.get(doc_idx, 0.0) # コンテキスト行を取得 context_content = self._get_context_lines(doc_idx, context_lines) result = { 'document_id': doc_idx, 'content': self.documents[doc_idx], 'context_content': context_content, 'combined_score': combined_score, 'keyword_score': keyword_score, 'vector_score': vector_score } results.append(result) # リランキング(オプション) if rerank: results = self.rerank_results(query, results) return results def _get_context_lines(self, doc_idx: int, context_lines: int) -> str: """ 指定された文書の前後の行を含むコンテキストを取得 """ start_idx = max(0, doc_idx - context_lines) end_idx = min(len(self.documents), doc_idx + context_lines + 1) context_parts = [] for i in range(start_idx, end_idx): if i == doc_idx: # メイン行は強調 context_parts.append(f">>> {self.documents[i]} <<<") else: context_parts.append(self.documents[i]) return "\n".join(context_parts) def rerank_results(self, query: str, results: List[Dict]) -> List[Dict]: """ 検索結果のリランキング より詳細な類似度計算で順位を調整 """ if len(results) <= 1: return results # クエリとの詳細な類似度を再計算 contents = [r['content'] for r in results] query_embedding = self.embedding_model.encode([query]) content_embeddings = self.embedding_model.encode(contents) detailed_similarities = cosine_similarity( query_embedding, content_embeddings )[0] # 新しいスコアで並び替え for i, result in enumerate(results): result['rerank_score'] = detailed_similarities[i] # 統合スコアを更新(重み付き平均) result['final_score'] = ( 0.7 * result['combined_score'] + 0.3 * detailed_similarities[i] ) # 最終スコアでソート results.sort(key=lambda x: x['final_score'], reverse=True) return results def search_with_context(self, query: str, top_k: int = 5, keyword_query: str = None) -> str: """ 検索結果を使ってコンテキストを生成 LLMに渡すためのプロンプト形式で返す """ results = self.hybrid_search(query, top_k, keyword_query=keyword_query) if not results: return "関連する文書が見つかりませんでした。" context_parts = [] for i, result in enumerate(results, 1): context_parts.append(f"[文書 {i}]") context_parts.append(f"スコア: {result['combined_score']:.4f}") context_parts.append(f"内容: {result['context_content']}") context_parts.append("") context = "\n".join(context_parts) prompt = f"""以下の検索結果を参考にして、質問に答えてください。 質問: {query} 検索結果: {context} 回答:""" return prompt # 使用例とデモ def demo(): # 外部ファイルから文書データを読み込み with open('lumi2.txt', 'r', encoding='utf-8') as file: sample_documents = [line.strip() for line in file if line.strip()] # システムの初期化 rag_system = HybridRAGSystem() # 文書を追加 rag_system.add_documents(sample_documents) # インデックスを構築 rag_system.build_index() # 検索デモ #query = "LUMINARの演奏者について教えて" query = "コンサートで演奏される曲を教えて" print(f"\n検索クエリ: '{query}'") print("=" * 50) # ハイブリッド検索の実行(キーワード検索とベクトル検索で別のクエリを使用) #keyword_query = "演奏者" # キーワード検索用の短いクエリ keyword_query = "楽曲" # キーワード検索用の短いクエリ results = rag_system.hybrid_search( query=query, top_k=20, keyword_query=keyword_query ) for i, result in enumerate(results, 1): print(f"\n結果 {i}:") print(f"文書ID: {result['document_id']}") print(f"統合スコア: {result['combined_score']:.4f}") print(f"キーワードスコア: {result['keyword_score']:.4f}") print(f"ベクトルスコア: {result['vector_score']:.4f}") print(f"コンテキスト内容:") print(result['context_content']) # コンテキスト生成のデモ print("\n" + "=" * 50) print("LLM用プロンプト:") print("=" * 50) context_prompt = rag_system.search_with_context(query, top_k=10, keyword_query=keyword_query) print(context_prompt) if __name__ == "__main__": demo() |

RAGの仕組みは、LLMの回答の精度に大きく関わるので、とても興味があります。
まだまだ第一歩でしょうか。
Categories: 未分類 タグ: LLM