
人工知能の強化学習フレームワークであるOpenAI Gym。あらかじめシミュレーションする世界(環境)が用意されているため、アルゴリズム部分に集中してコーディングできます。この環境はレトロゲームなど多数あり、楽しく学べます。
https://gym.openai.com/
以下、CarPoleという棒が倒れないように制御するモデルを試したときのメモです。
(昔、リアルのものをファジー理論のデモとかでみたような記憶が・・)
まず、環境に対してアクションを起こし、それの状態を表示するテストを対話的にやってみました。
-
環境: python 3.6.10 / Anaonda 4.8.3 / macOS High Sierra 10.13.6
参考書籍: 「OpenAI Gym/Baselines」(布留川英一 著)
参考サイト: https://qiita.com/ishizakiiii/items/75bc2176a1e0b65bdd16
上記操作をすると、下記のような状態に変化します。
actionはそれぞれのモデルで決まっており、このケースでは0は左、1は右に台車を移動させます。
-
o:observation 観測
r:reward 報酬
d:done エピソード終了フラグ
i:infomation 詳細情報
次に公式のgithubにあるサンプルを動かしてみました。
https://github.com/openai/gym/blob/master/examples/agents/cem.py
$ python cem.py
INFO: Making new env: CartPole-v0
INFO: Creating monitor directory /tmp/cem-agent-results
INFO: Starting new video recorder writing to /tmp/cem-agent-results/openaigym.video.0.643.video000000.mp4
INFO: Starting new video recorder writing to /tmp/cem-agent-results/openaigym.video.0.643.video000001.mp4
INFO: Starting new video recorder writing to /tmp/cem-agent-results/openaigym.video.0.643.video000008.mp4
Iteration 0. Episode mean reward: 25.640
INFO: Starting new video recorder writing to /tmp/cem-agent-results/openaigym.video.0.643.video000027.mp4
Iteration 1. Episode mean reward: 86.040
INFO: Starting new video recorder writing to /tmp/cem-agent-results/openaigym.video.0.643.video000064.mp4
Iteration 2. Episode mean reward: 171.120
Iteration 3. Episode mean reward: 196.080
Iteration 4. Episode mean reward: 198.480
INFO: Starting new video recorder writing to /tmp/cem-agent-results/openaigym.video.0.643.video000125.mp4
このサンプルは動画を出力してくれたので、これを添付します。(わかりやすい!)
最後に、書籍を参考にフレームワークの基本になる部分を実装してみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import gym import os from stable_baselines.common.vec_env import DummyVecEnv from stable_baselines import PPO2 from stable_baselines.bench import Monitor log_dir = './log/' os.makedirs(log_dir, exist_ok=True) env = gym.make('CartPole-v1') env = Monitor(env, log_dir, allow_early_resets=True) env = DummyVecEnv([lambda: env]) model = PPO2('MlpPolicy', env, verbose=1) #model.learn(total_timesteps=100000) model.learn(total_timesteps=10000) model.save('model01') #model = PPO2.load('model01') state = env.reset() while True: env.render() action, _ = model.predict(state, deterministic=True) state, rewards, done, info = env.step(action) if done: break env.close() |
(上記サイトのobservationは書籍ではstateになっています。)
当然ですが、学習の回数が多いと倒れにくくなります。このあたりを回数を変えてシミレーションしてみると面白いです。基本的に見栄えは上記動画と同じです。モデルの生成には時間がかかりますので、2回目以降は再利用します。
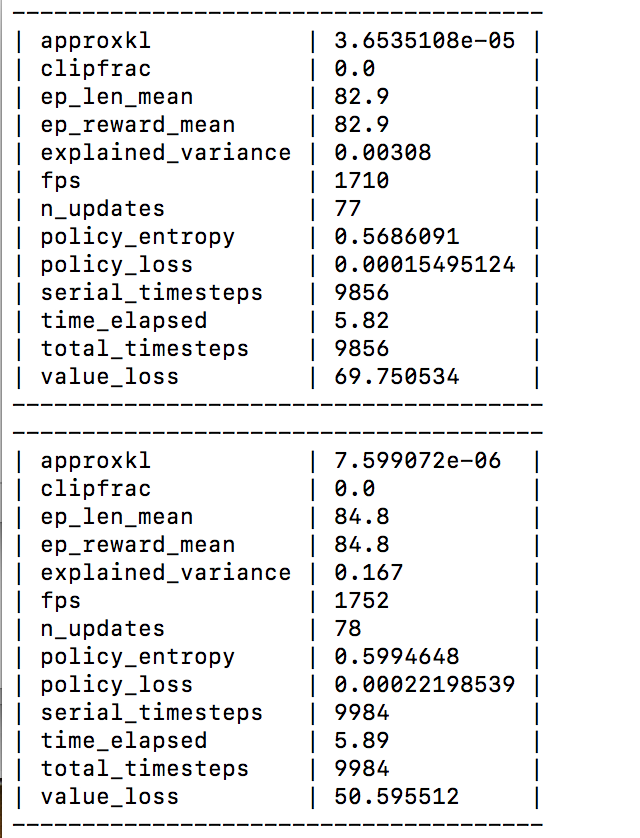
ログによって強化学習ができているかどうか監視することができます。
csvファイルで出力されたログをExcelでプロットしてみました。
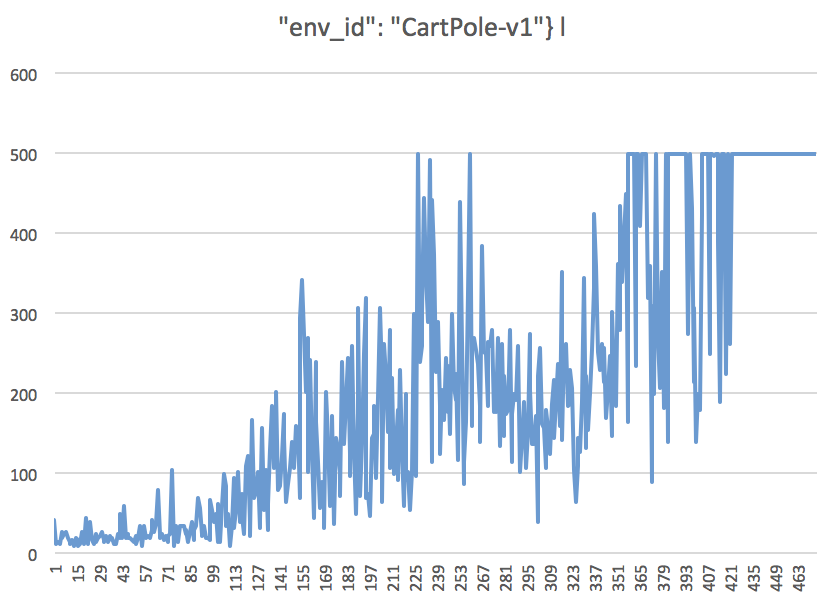
これは下記、ep_len_meanまたはep_reward_meanに相当します。
まだまだたくさんの環境があり、一通り見るだけでも大変です。以下は環境の一覧をみるコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import sys import gym from gym import envs for spec in envs.registry.all(): print(spec.id) try: e = gym.make(spec.id) o = e.reset() e.render() input() e.close() except KeyboardInterrupt: sys.exit() except: print("exception!") |
アルゴリズムやモデルがプリセットされており、分析に力点が置かれているフレームワークという印象を受けます。このようにどんなモデルであってもインターフェイスが共通化されていると、いろいろと効率的にできそうです。
かなり荒い説明になっていますので、ぜひ書籍をご覧ください。
以上、このフレームワークの入り口に立つ意味で、書いてみました。
(このブログを始めた当初はPythonのAIネタは多かったのですが・・久しぶりになりました。)