
末尾再帰の最適化でマシン語に久しぶりに触れてみようと思いました。マシン語を見ているとプログラムというのは、CPUに渡すデータである、とも感じとれます。
末尾再帰については、下記ブログで5年くらい前に取り上げました。
http://bitlife.me/archives/date/2011/11
これをLinuxでテストし、バイナリーエディットもしてみました。
環境: Ubuntu 16.04 LTS
recursion.c
|
1 2 3 4 5 6 7 8 9 10 |
#include<stdio.h> void loop(int x) { printf("%d ", x); loop(x + 1); } int main() { loop(1); } |
cc -o recursion recursion.c
cc -o recursion_t -O2 recursion.c
recursion_tのように最適化すると、関数の再帰呼び出しがアドレスジャンプになります。
cc -S recursion.c
cc -O2 -S -o recursion_t.s recursion.c
recursion.s
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
.file "recursion.c" .section .rodata .LC0: .string "%d " .text .globl loop .type loop, @function loop: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movl %edi, -4(%rbp) movl -4(%rbp), %eax movl %eax, %esi movl $.LC0, %edi movl $0, %eax call printf movl -4(%rbp), %eax addl $1, %eax movl %eax, %edi call loop nop leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size loop, .-loop .globl main .type main, @function main: .LFB1: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $1, %edi call loop movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE1: .size main, .-main .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.2) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits |
recursion_t.s
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
.file "recursion.c" .section .rodata.str1.1,"aMS",@progbits,1 .LC0: .string "%d " .section .text.unlikely,"ax",@progbits .LCOLDB1: .text .LHOTB1: .p2align 4,,15 .globl loop .type loop, @function loop: .LFB23: .cfi_startproc pushq %rbx .cfi_def_cfa_offset 16 .cfi_offset 3, -16 movl %edi, %ebx .p2align 4,,10 .p2align 3 .L2: movl %ebx, %edx movl $.LC0, %esi movl $1, %edi xorl %eax, %eax addl $1, %ebx call __printf_chk jmp .L2 .cfi_endproc .LFE23: .size loop, .-loop .section .text.unlikely .LCOLDE1: .text .LHOTE1: .section .text.unlikely .LCOLDB2: .section .text.startup,"ax",@progbits .LHOTB2: .p2align 4,,15 .globl main .type main, @function main: .LFB24: .cfi_startproc subq $8, %rsp .cfi_def_cfa_offset 16 movl $1, %edi call loop .cfi_endproc .LFE24: .size main, .-main .section .text.unlikely .LCOLDE2: .section .text.startup .LHOTE2: .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.2) 5.4.0 20160609" .section .note.GNU-stack,"",@progbits |
末尾再帰が最適化されているものはprintfの後に関数呼び出し(call)がなくなっているのがわかります。通常の再帰だと実行時スタックがオーバーフローして以下のようにエラーとなります。
./recursion
…….(省略)
24 261725 261726 261727 261728 261729 261730 261731 261732 261733 261734 261735 261736 261737 261738 261739 261740 261741 261742 261743 261744 261745 261746 261747 261748 261749 261750 261751 261752 261753 261754 261755 261756 261757 261758 261759 261760 261761 261762 261763 261764 261765 261766 261767 261768 261769 261770 261771 261772 261773 261774 261775 261776 261777 261778 261Segmentation fault (コアダンプ)
最適化されるとアドレスジャンプとなり無限にループします。
./recursion_t
…….(省略)
1968219 1968220 1968221 1968222 1968223 1968224 1968225 1968226 1968227 1968228 1968229 1968230 1968231 1968232 1968233 1968234 1968235 1968236 1968237 1968238 1968239 1968240 1968241 1968242 1968243 1968244 1968245 1968246 1968247 1968248 1968249 1968250 1968251 1968252 1968253 1968254 1968255 1968256 1968257 1968258 1968259 1968260 1968261 1968262 1968263 1968264 ^C
(無限につづく)
さてここでちょっと遊んでコアダンプする原因となる関数呼び出しをバイナリエディットして無効にしてみたいと思います。
cp recursion recursion_e
objdump -D recursion > recursion.dmp
vi -b recursion_e
objdump -D recursion_e > recursion_e.dmp
recursion.dmp抜粋
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
0000000000400526 <loop>: 400526: 55 push %rbp 400527: 48 89 e5 mov %rsp,%rbp 40052a: 48 83 ec 10 sub $0x10,%rsp 40052e: 89 7d fc mov %edi,-0x4(%rbp) 400531: 8b 45 fc mov -0x4(%rbp),%eax 400534: 89 c6 mov %eax,%esi 400536: bf f4 05 40 00 mov $0x4005f4,%edi 40053b: b8 00 00 00 00 mov $0x0,%eax 400540: e8 bb fe ff ff callq 400400 <printf@plt> 400545: 8b 45 fc mov -0x4(%rbp),%eax 400548: 83 c0 01 add $0x1,%eax 40054b: 89 c7 mov %eax,%edi 40054d: e8 d4 ff ff ff callq 400526 <loop> 400552: 90 nop 400553: c9 leaveq 400554: c3 retq |
このファイルより編集箇所を特定します。
40054d番地のcallqをnop(C9)で埋めることにします。
実行ファイルをviエディタのバイナリーモードで開き、コマンド
:%!xxd
でバイナリーモードに
:%!xxd -r
で、元にもどします。
:w
で保存します。
バイナリーモードのときに、e8d4 d4ff などの文字列で検索をして場所を特定します。
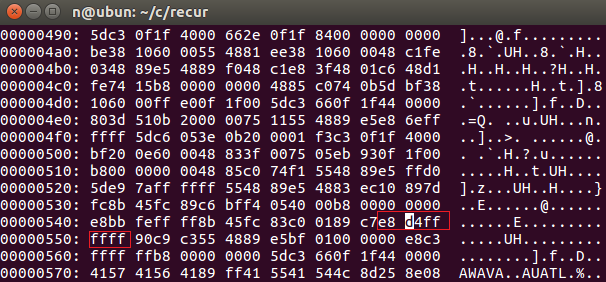
e8から5バイトをc9で埋めます。nopというのはNo Operationの略で何もしない、という意味です。サイズを変えられないバイナリファイルの編集時によく使います。
(条件分岐などを操作すると結構いろいろとできますが要注意)
recursion_e.dmp抜粋
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
0000000000400526 <loop>: 400526: 55 push %rbp 400527: 48 89 e5 mov %rsp,%rbp 40052a: 48 83 ec 10 sub $0x10,%rsp 40052e: 89 7d fc mov %edi,-0x4(%rbp) 400531: 8b 45 fc mov -0x4(%rbp),%eax 400534: 89 c6 mov %eax,%esi 400536: bf f4 05 40 00 mov $0x4005f4,%edi 40053b: b8 00 00 00 00 mov $0x0,%eax 400540: e8 bb fe ff ff callq 400400 <printf@plt> 400545: 8b 45 fc mov -0x4(%rbp),%eax 400548: 83 c0 01 add $0x1,%eax 40054b: 89 c7 mov %eax,%edi 40054d: 90 nop 40054e: 90 nop 40054f: 90 nop 400550: 90 nop 400551: 90 nop 400552: 90 nop 400553: c9 leaveq 400554: c3 retq |
バイナリが書き換えられているかどうか確認できました。
これを実行すると、
./recursion_e
1
loopが一回しか呼ばれないので、1のみ表示して終了します。
今回バイナリーの話題を取り上げるきっかけとなったのは、最近必要性が増していような気がしているためです。
以前も下記で取り上げましたが、
http://decode.red/blog/20150913427/
FPGAやGPUプログラミングの必要性についても感じます。
コンピュータの進化がムーアの法則に従っているときはよかってのですが、そのような進化ができなくなり、かつ要求される処理の負荷が増大していることが起因しているからだと思います。
コンピュータリソースに余裕があるときは、人間にとってやさしい手法、生産性を高める手法が開発の現場でも用いられますが、今後は再びコンピュータリソースに余裕がなかった時代に戻る傾向にあるような気がします。(C言語は遅いからアセンブラで組め、などと言われた時代もあった)
難解な関数型言語が注目されるのもこの影響からだと思われます。
今回とりあげた末尾再帰についてもこの傾向によるところがあります。
マシン語のアドレスジャンプはBASICでいうGOTO文(C言語でもありますが)と同じで、構造化プログラミングでは使ってはいけないものとされていますが、再帰処理では欠かせないものになっています。
最近BASICから学ぶことが多い・・かも。。