
以前から気になっていたword2vecを動かしてみました。
これは単語間の類似性をベクトルとして計算します。
参考 : https://code.google.com/p/word2vec/
やはり実際に自分でやってみるといろんなことに気づきました。ファイルがとにかく大きくて処理に時間がかかること。マシンスペックもメモリ、CPUともできるかぎり高いレベルのものがあった方がいいということです。(VMはちょっときついかも)
環境: Ubuntu 14.04 / Virtual Box / Windows 8.1
セットアップ
svn checkout http://word2vec.googlecode.com/svn/trunk/
cd trunk
make
wget http://mattmahoney.net/dc/text8.zip -O text8.gz
gzip -d text8.gz -f
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
ここまでで下記ツールを使う準備ができました。
./distance vectors.bin
./word-analogy vectors.bin
./demo-word.sh
./demo-phrases.sh
の内容が参考になります。
demo-phrases.shは、word2vecに膨大な時間がかかるので、あきらめました。
どんなファイルかイメージするために、text8の冒頭部分です。

./word2vec -train text8 -output vectors.txt -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -iter 15
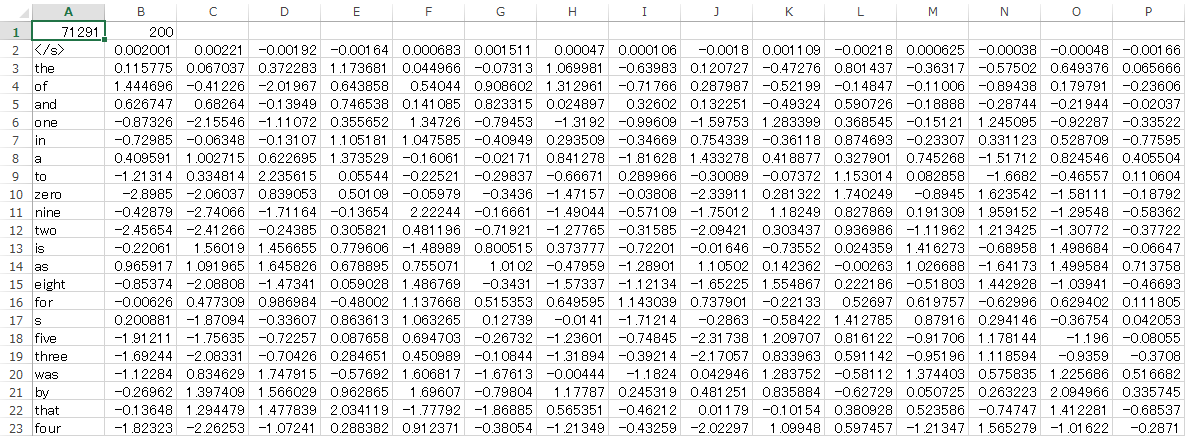
上のようにvectors.binをテキスト出力することもできます。以下がその内容で、
見やすくするためにExcelに表示しました。200次元のベクトルになっています。
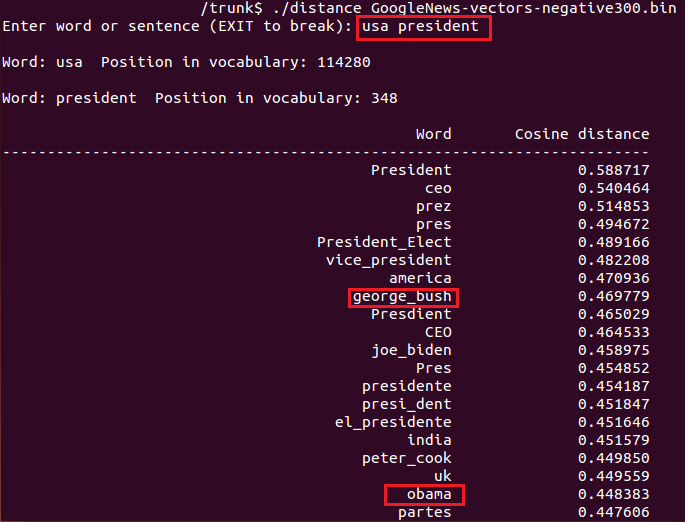
ツールを使って、近い距離にある単語を出力してみます。vectors.binではあまり十分な結果が得られなかったので、word2vecのサイトにあった、GoogleNews-vectors-negative300.bin を使いました。
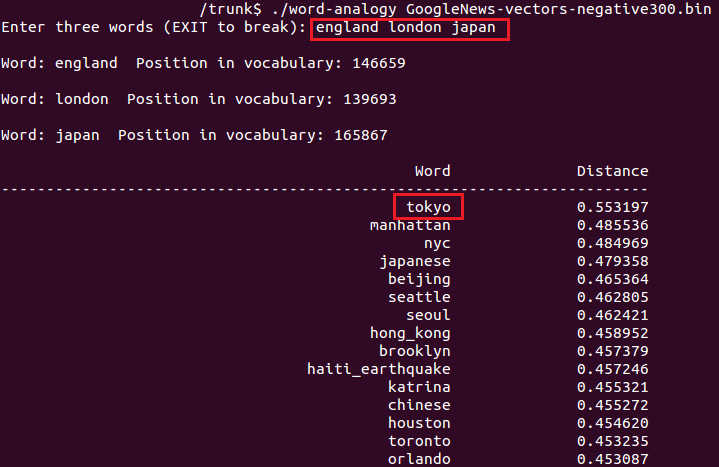
次は、前二つの単語の関係から、三つ目の単語から類推できる単語を出力してみます。
今回デフォルトで用意されたデータばかり使いましたが、自分で目的にあったデータを収集すれば、期待どおりの結果を出してくれそうだと思いました。