
Posted on 2014/06/15, 10:38 PM By admin22
データフィッテングを通して、Rの手法をより理解したいと思います。
今回いろいろと試してみて、functionにpredictを使った書き方がとても便利に感じました。これによりモデリングと関数の実行を一緒にできます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
par(col.axis='firebrick2', col.lab='white', bg='gray33', fg='white') f2 <- function(x,y){predict(lm(y~x + I(x^2)))} f3 <- function(x,y){predict(lm(y~x + I(x^2) + I(x^3)))} f4 <- function(x,y){predict(lm(y~x + I(x^2) + I(x^3) + I(x^4)))} x0 <- 1:100/100 y0 <- 3 * sin(x0 * 10) + rnorm(x0) plot(x0, y0) lines(x0, f2(x0,y0), col="cyan") lines(x0, f3(x0,y0), col="green") lines(x0, f4(x0,y0), col="yellow") |
対象データは、sin関数を正規分布で散らしたものを使いました。
これを2次、3次、4次曲線でフィッテングします。

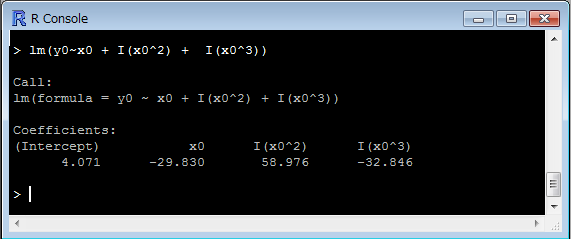
以下は、f3と同じになります。係数を確認するときはこのように実行する必要があります。
確認のため、下に0.2ずらした位置にPlotしました。
|
1 2 |
ce <- coef(lm(y0~x0 + I(x0^2) + I(x0^3))) lines(x0, ce[1] + ce[2]*x0 + ce[3]*x0^2 + ce[4]*x0^3 - 0.2, col="blue") |
Categories: 未分類 タグ: R