
Posted on 2014/05/24, 6:07 PM By admin22
記念すべき第一回目は、Pythonの自然言語処理ツールです。
構文解析の第一歩として、まず単語の出現頻度をグラフにしてみました。
サンプルの文章は、上記サイトの冒頭のドキュメントです。
環境 : Ubuntu 14.04 LTS
準備 :
pip install nltk
python
>> import nltk
>> nltk.download()
# -*- coding: utf-8 -*-
import nltk
import pylab as pl
import collections as cl
str = """
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet,
...(以下省略)
"""
tokens = nltk.word_tokenize(str)
counter = cl.Counter(tokens)
cnt = []
word = []
x = []
i = 0
max = 20
for w, c in counter.most_common():
tag = nltk.pos_tag([w])
if tag[0][1] in ('DT', 'CC', 'IN', 'TO', 'VBZ', ',', "<code></code>", "''", 'VB'):
continue
word.append(w)
cnt.append(c)
x.append(i)
i += 1
if i >= max:
break
pl.bar(x,cnt)
pl.xticks(range(len(word)), tuple(word),rotation=60)
pl.show()
重要でない冠詞や前置詞などは無視するようにしています。単語の品詞を判別できる点がこのようなライブラリを使う大きなメリットですね。
結果 :
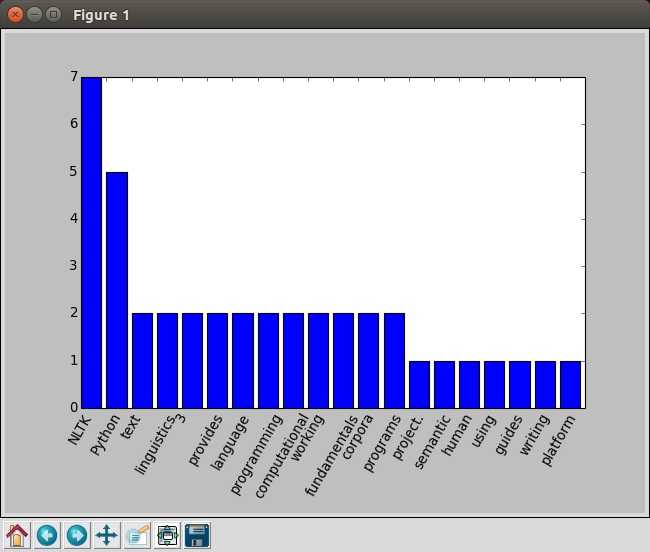
これを入口にして、さらに進めていきたいと思います。
No comments yet Categories: 未分類 タグ: Machine Learning, Python
コメントを残す
コメントを投稿するにはログインしてください。